RegExp — друг человека!

Знаете комбинацию клавиш Ctrl + F? А видели при поиске галочку RegExp или значок (.*) ? Эта галочка там стоит не зря. Часто при серьёзной работе с текстом (или кодом) нам нужен более гибкий механизм, чем просто поиск ровно той комбинации символов, которую мы написали. И этим механизмом стал RegExp, или регулярные выражения, ставший интернет-мемом за свою непонятность и кажущуюся абсурдность. Сегодня мы развеем эти предрассудки и выясним, что регулярные выражения — это не страшно.
Мы будем рассматривать регулярные выражения на примере поиска в Gedit, но если вы используете Windows, то можете использовать Notepad++. Также подойдут редакторы кода вроде Visual Studio Code или онлайн-редакторы вроде Google Docs. Огромное количество текстовых редакторов поддерживают регулярные выражения, надо просто поставить нужную галочку. Текст используем вот этот.
Cтатья огромная, но она позволит вам гораздо эффективнее работать с поиском и заменой текста — очень частой процедурой для тех, кто много работает с текстом. Регулярные выражения, если и не сделают вас всесильным, то уж точно серьёзно прокачают ваш кулхацкерский скилл, и даже если вы не сможете придумать сколько-нибудь полезное применение этим знаниям, вы всегда сможете козырнуть ими перед своими менее компьютерно-образованными коллегами, ведь это так важно! Итак, поехали.
Иногда сигара — это просто сигара
Если мы напишем обычный текст, то регулярное выражение будет искать этот текст. Очень просто и знакомо. Например, так: слова, циф3рки, пробелы.
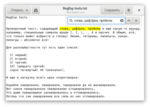
Но есть символы, которые имеют особый смысл в регулярных выражениях, и их нельзя вставить в строку просто так. Список этих символов следующий: [\^$.|?*+()
И если мы введём символы вроде ], {, \, ., $, то не сможем ничего найти.
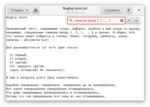
И как же быть, если мы хотим найти, например, такой банальный символ, как точка? RegExp предлагает перед каждым таким символом ставить обратную косую черту. То есть, \. будет искать точку, \$ будет искать доллар, а \\ — обратную косую черту. Да, это как-то неудобно, но это единственный недостаток регулярных выражений, далее будут только преимущества! Так что, вводим символы вроде \], \{, \\, \., \$ и идём дальше.
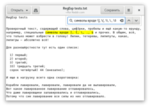
Тут я “заэкранировал” даже больше символов, чем нужно, так, для перестраховки. Мне кажется, что ставить обратную косую черту перед каждым странным символом проще, чем запоминать, какие символы входят в состав “особых”, а какие нет.
А кое-кто наверняка при виде обратной косой черты сразу вспомнил об управляющих символах. Ну, это когда \t означает таб, а \n или \r\n означают перенос строки. Так вот, эти штуки могут работать вместе с регулярными выражениями. Иногда нужна дополнительная галка для использования управляющих символов.
Далее по списку…
Все ведь сталкивались с ситуацией, когда надо найти слово с буквой “ё” и приходится отдельно искать ещё и с буквой “е”, потому что в русском языке это, видите ли, допустимая замена? Так вот, в регулярных выражениях, вместо буквы можно поставить квадратные скобки (на этот раз без обратной косой черты), в которых будет указано несколько букв, которые нам подходят. Например, ещ[ёе]
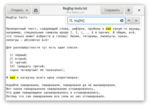
А при помощи выражения [аеёиоуыэюя], можно найти в тексте все гласные. Стоит также отметить, что регулярные выражения, как и обычный поиск, могут работать в режиме игнорирования регистра (большие и маленькие буквы эквивалентны) или же в режиме чувствительности к регистру, и тогда придётся уже писать [аеёиоуыэюяАЕЁИОУЫЭЮЯ]. Для простоты в своих примерах я использовал поиск не чувствительный к регистру.
Но простое перечисление — это ещё не всё, что умеют квадратные скобки. Например, можно указывать диапазон между символами. Так, выражение [0-9] найдёт все цифры.
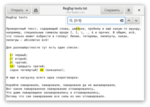
Такие диапазоны можно комбинировать с другими диапазонами и с раздельным перечислением символов. Так, [б-джзй-нп-тф-щ] найдёт все согласные.
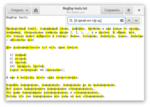
Отмечу, что вопреки всякой логике, буква “ё” не входит в диапазон [а-я], так что для охвата всех букв русского языка следует писать [а-яё], или, с учётом регистра, [а-яА-ЯёЁ].
И ещё одна полезная вещь. Если первым символом в квадратных скобках будет крышка, то мы найдём всё, что НЕ входит в указанный список. Вот так можно выделить всё, кроме согласных [^б-джзй-нп-тф-щ]
Too long didn’t read (слишком длинно — не читал)
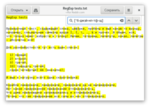
Особо популярные наборы символов выведены в специальные комбинации. \d означает цифру, \w — букву, цифру или подчёркивание, \s — разрыв (пробел, таб, перенос строки и т.д.).
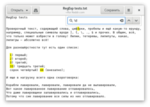
А чтобы сымитировать крышку, достаточно букву после косой черты написать с большой буквы: \D — всё, кроме цифр, \S — всё, кроме пробелов и т.д.
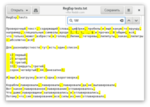
Надо отметить, что некоторые редакторы, например, Visual Studio Code или Google Docs по какой-то причине не включают кирилические символы в \w. Так что, при необходимости придётся использовать куда более длинное [\wа-яА-ЯёЁ].
Нам, татарам, всё равно
А если нам плевать на всё, и нам подойдёт совершенно любой символ, то можно просто поставить точку. Вот, например, все символы, окружённые буквой “о”: о.о
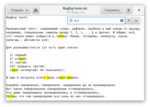
Но если мы хотим, чтобы это обязательно было частью слова, и мы не хотим пробел в результатах, то точка уже не подойдёт, и нужно будет ввести о\wо
Три кинокамеры заграничных, три портсигара отечественных…
Иногда нам нужно найти несколько совпадений указанного правила. Тогда просто после символа или после скобок (не только квадратных, но и тех, до которых мы ещё не дошли) можно поставить фигурные скобки, в которых будет указано количество повторений. Вот так можно найти, где три согласные идут подряд: [б-джзй-нп-тф-щ]{3}
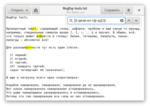
А если не обязательно три, а, например, от двух до четырёх? Тогда два и четыре можно указать в скобках через запятую: [б-джзй-нп-тф-щ]{2,4}
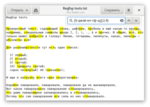
Второе число можно не указывать, тогда количество не будет ограничено по максимуму. Вот так мы найдём три и более согласных подряд: [б-джзй-нп-тф-щ]{3,}
Короче
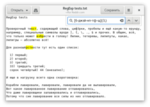
Как и с группами символов, особо популярные варианты количества имеют свои сокращения. Плюс означает от одного до бесконечности, то есть, {1,}. Вот так мы можем найти любое число, включая двузначные, трёхзначные и т.д.: \d+
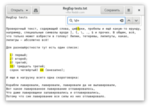
Звёздочка означает от нуля до бесконечности — {0,} — что бывает очень полезно, когда определённых символов может и не быть, и нас это устраивает. Вот так мы найдём все слова с корнем “лавир”: \w*лавир\w*
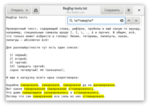
Вопросительный знак означает один символ или ни одного, иными словами, {0,1}. Это поможет справиться с беглыми гласными в корнях. Например, из корня слова “один” периодически пропадает буква “и”. Нам поможет вопросительный знак: \w*оди?н\w*
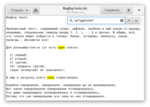
Горшочек, не вари!
Допустим, мы хотим найти все номера нашего странного списка. Вроде, всё просто: сначала таб, потом сколько-то цифр, букв или пробелов, а потом закрывающая скобка. Но когда мы введём \t.*\) то увидим не то, что ожидали.
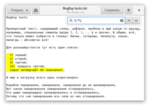
Почему-то берётся не первая закрывающая скобка, а последняя. Всё дело в том, что звёздочка пытается захватить столько символов, сколько возможно (так называемый, жадный поиск), и выбирая из двух закрывающих скобок в строке, выбирается та, которая позволит звёздочке захапать максимальное количество символов.
Тут стоит указать, что существует многострочный режим работы RegExp (можно выставить специальной галкой), который в моих примерах выключен (это, как правило, настройка по умолчанию). Так что, если включить многострочный поиск, то звёздочка сожрёт ещё больше символов, переходя на всё новые строки, и вообще не видя краёв.
Так как же усмирить жадный поиск? — Просто поставить после указания количества (после закрывающей фигурной скобки или после сокращённого символа, в нашем случае — после звёздочки) вопросительный знак. Этот знак переведёт нашу звёздочку в ленивый режим и будет теперь стремиться поглотить как можно меньше символов: \t.*?\)
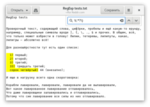
Как писалось выше, вопросительный знак можно ставить и после фигурных скобок, и после плюса, и даже после другого вопросительного знака (который, так то, означает от нуля до одного).
Пролетарии всех стран…
А ещё, регулярные выражения позволяют объединять несколько символов (правил) в блоки простыми круглыми скобками. Зачем? — чтобы работать с несколькими символами как с одним. Вот так, например, мы можем найти места, где буквы “ли” идут встречаются два раза подряд: (ли){2}
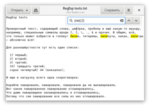
А ещё (и это супер-круто), текст, найденный по скобке, запоминается, и можно указать, что вам нужен ещё один, такой же. Скобок может быть несколько, так что то, что было найдено по первой скобке, можно искать по комбинации \1, во второй — \2, и так далее. Сложновато, так что вот пример того, как найти любые две буквы, тут же повторённые: (\w\w)\1
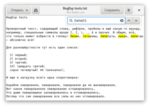
Для понимания того, в чём тут фишка, можно сравнить, чем отличаются результаты от (\w\w)\1 и от (\w\w)(\w\w).
Помните, как мы искали символы, расположенные между двумя буквами “о”? А вот так мы можем найти символы, расположенные между любыми одинаковыми символами: (\w)\w\1
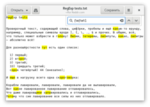
Не знаю зачем, но можно сделать так, чтобы содержание скобки нельзя было повторить по \1, \2 и всего такого. Для этого в начале скобок нужно написать вопросительный знак с двоеточием: (?:меня козлёнок не посчитает). Примера показывать не буду, потому что ну его, но это работает, можете проверить сами.
Обмен
Всё круто с поиском, но есть ещё функция замены текста. Могут ли регулярные выражения так же круто помочь нам там? — Могут! Например, можно использовать в тексте замены содержимое скобок из поиска. Это работает так же, как и \1 и \2, но пишется иначе: $1 и $2. Вот так мы вставим во все скобки указание на то, что это примечание от переводчика: ищем (\()(.*?\)), заменяем на $1от переводчика: $2


Наблюдательный читатель наверняка заметил, что для этого примера я использовал не Gedit, а Visual Studio Code. Дело в том, что Gedit, как и некоторые другие редакторы, не поддерживает подобный синтаксис. Если ваш редактор не отрабатывает вышеуказанный пример, можно попробовать вместо $1, $2 и т.д. использовать более привычные \1, \2 и т.д.. Зачастую, это работает. Так, для Gedit и прочих, нужно писать следующее: ищем (\()(.*?\)), заменяем на \1от переводчика: \2.
Ещё можно использовать весь найденный текст в замене, он обозначается символами $&. Например, если мы вдруг перестали верить в то, что второй является тем, за кого себя выдаёт, можем обернуть его недоверительной формулировкой: ищем второй, заменяем на так называемый, “$&”


А в тех редакторах, которые эту фишку не поддерживают, придётся выкручиваться с тем, что имеем. Например, обернуть весь запрос в скобки и использовать их содержимое, как в прошлом примере: ищем (второй), заменяем на так называемый, “\1”.
Ну, и в случае, если вам нужно вставить текст, содержащий, собственно, знак доллара, то его можно вставить вот так: $$. И снова, в определённых редакторах доллар можно вставить более привычным \$.
Не в фокусе
И обратно к поиску. На этот раз поговорим о правилах, которые указывают на расположение искомых строк, но не влияют на выделение. Например, можно указать, что мы ищем что-то на границе слова, в начале или конце строки и так далее. Так, \b означает границу слова (а \B — не границу слова), ^ — начало строки, $ — конец строки. Теперь мы можем выделить все слова, начинающиеся с буквы “в”: \bв\w+.
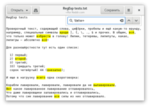
А если этих нескольких вариантов недостаточно, то можно описать свои, любой сложности. Если написать в конце регулярного выражения скобки с восклицательным знаком и знаком равно, то будут искаться те фрагменты текста, после которых идёт указанное выражение (само выражение в выделение не попадёт). Вот так мы найдём все слова, после которых стоит запятая: \w+(?=,)
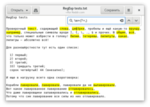
Или можно указать, что какое-либо выражение ни в коем случае не должно находиться после нашего выделения, заменив знак равно на восклицательный знак. Чтобы выбрать все числа, не являющиеся номером списка (после них не стоит скобка), введём \b\d+\b(?!\))
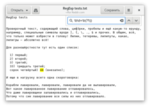
Вариативность
В заключение хочется рассказать о вариативности. Если мы допускаем несколько правил, по которым мы можем найти нужный фрагмент (например, хотим найти синонимы или разные формы слов), мы можем разделять такие допустимые правила знаком вертикальной черты. Вот так мы выделим все слова, связанные с единицей: \w*оди?н\w*|\w*перв\w*
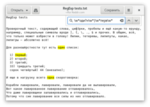
Эта штука становится гораздо полезнее, если сочетается с круглыми скобками. Предлагаю читателю самому поэкспериментировать с этим и всеми предыдущими правилами.
Всё!

Вот и всё, что я хотел сказать о регулярных выражениях. Вы очень усидчивы, если дочитали до этого места. Надеюсь, это время было потрачено не зря.